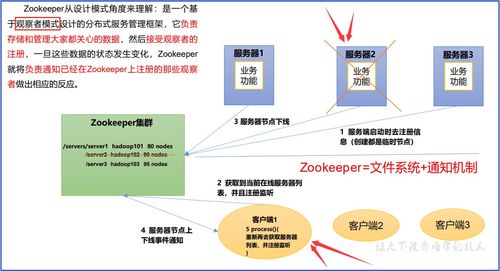
ZooKeeper是一個分布式的、開源的協調服務框架,廣泛應用于分布式系統中。它通過簡單的數據模型和API,為分布式應用提供一致性和可靠性保障。
一、ZooKeeper工作機制
ZooKeeper采用主從架構,其中包含一個Leader節點和多個Follower節點。客戶端可以連接到任意節點進行讀寫操作。工作機制主要包括以下幾個方面:
- 選舉機制:當Leader節點失效時,Follower節點通過Zab協議進行選舉,選出新的Leader。
- 請求處理:寫請求由Leader處理,通過兩階段提交確保數據一致性;讀請求可以由任意節點處理,提高性能。
- 數據同步:Leader節點將寫操作廣播給Follower,確保所有節點數據一致。
- 會話管理:客戶端與ZooKeeper建立會話,通過心跳機制維持連接,超時則會話失效。
二、ZooKeeper特點
ZooKeeper具有以下顯著特點:
- 順序一致性:客戶端的操作按順序執行。
- 原子性:更新操作要么成功,要么失敗,沒有中間狀態。
- 單一系統映像:無論連接到哪個節點,客戶端看到的數據視圖都是一致的。
- 可靠性:一旦更新生效,數據將持久化,直到被覆蓋。
- 實時性:在一定時間范圍內,客戶端能讀到最新數據。
- 高可用性:通過多節點部署,避免單點故障。
三、ZooKeeper數據結構
ZooKeeper的數據模型類似于文件系統的樹形結構,每個節點稱為ZNode。ZNode具有以下特性:
- 路徑:每個ZNode有唯一的路徑,如
/app/service1。 - 數據存儲:ZNode可以存儲少量數據(默認不超過1MB)。
- 節點類型:
- 持久節點:創建后一直存在,直到顯式刪除。
- 臨時節點:與客戶端會話綁定,會話結束則節點自動刪除。
- 順序節點:節點名會自動附加單調遞增的序列號。
- 版本控制:每個ZNode有數據版本和子節點版本,用于樂觀鎖控制。
四、ZooKeeper提供的服務
ZooKeeper提供多種核心服務,支持分布式系統開發:
- 命名服務:通過ZNode路徑實現服務注冊與發現。
- 配置管理:將配置信息存儲在ZNode中,客戶端監聽變化以實現動態配置更新。
- 集群管理:通過臨時節點監控節點狀態,實現故障檢測和主節點選舉。
- 分布式鎖:利用ZNode的排他性實現互斥鎖,或通過順序節點實現公平鎖。
- 隊列管理:通過順序節點實現先進先出隊列或屏障同步。
五、數據處理服務
在數據處理方面,ZooKeeper提供以下功能:
- 數據發布/訂閱:客戶端可以監聽ZNode的數據變化,當數據更新時接收通知。
- 數據一致性保證:通過Zab協議確保所有節點數據一致。
- 事務支持:ZooKeeper支持原子性操作,多個操作可以封裝為一個事務。
- 數據持久化:數據會持久化到磁盤,同時內存中維護數據樹以提高性能。
- 數據監控:通過Watch機制,客戶端可以監控ZNode的創建、刪除、數據變更等事件。
ZooKeeper作為分布式系統的協調核心,以其可靠性和簡單性成為眾多大型系統的基石。理解其工作機制、特點、數據結構和服務,對于設計和開發分布式應用至關重要。